
Phalanx Arena is an ancient-battle simulator I have been building. My slightly weird idea was to see if large language models can actually command ancient armies, and how they would fare against each other.
The engine borrows from the classic ruleset De Bellis Antiquitatis: a grid-based map, action points, limited manoeuvres, shooting and close combat, flee-and-pursuit, and morale-triggered army breaks. The goal is to simulate Hellenistic armies (4th–1st century BC), with pike phalanxes, medium infantry, skirmishers, light and heavy cavalry, and the occasional elephant.


(Why Hellenistic armies? Because they are very geometric, varied, symmetrical, and tactically interesting. Also, I just like this period of history.)
This weekend I ran a full round-robin tournament. Seven LLMs, every pair playing 8 games (mirrored across both sides of the map), 168 games total, on a simple scenario with an almost empty battlefield (just small hills and forests on each side, symmetrical) and the same army roster:
- OpenAI GPT-5.5
- Claude Opus 4.7
- Gemini 3.1 Pro
- Grok 4.20 Reasoning
- Mistral Large 3
- OpenAI GPT-5.4 Mini
- Mistral Small
Each took the field 48 times, paired against every other competitor.
The results
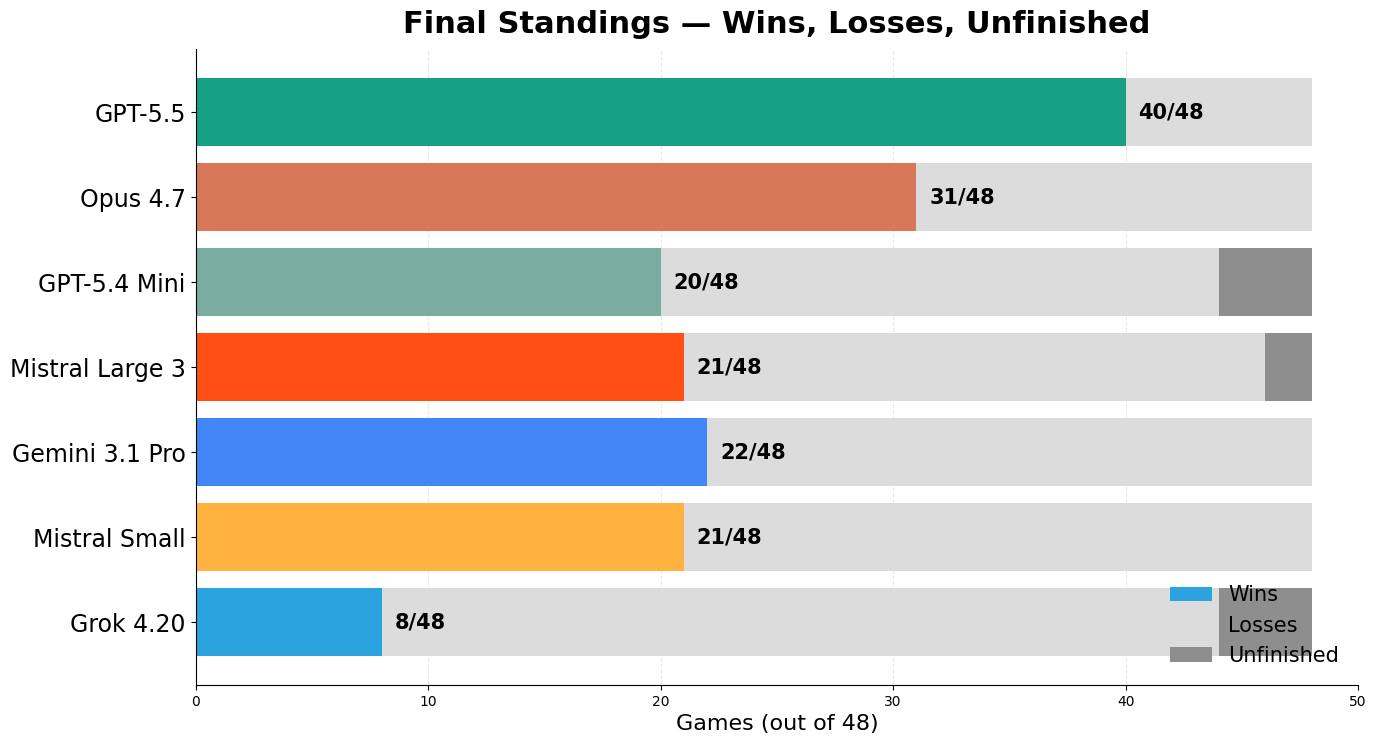
They were quite interesting! GPT-5.5 won very clearly: 40 wins out of 48, undefeated across all six pairings. Claude Opus 4.7 was a solid second at 31 wins, beating every model except GPT-5.5.
The middle of the table was much messier. Gemini 3.1 Pro, GPT-5.4 Mini, and Mistral Large 3 all finished on 22 points, with Mistral Small just behind at 21. Head to head, Mistral Large beat Gemini 5–3, which is quite surprising!
Grok 4.20 was the clear loser: 8 wins, 36 losses, 4 unfinished games.
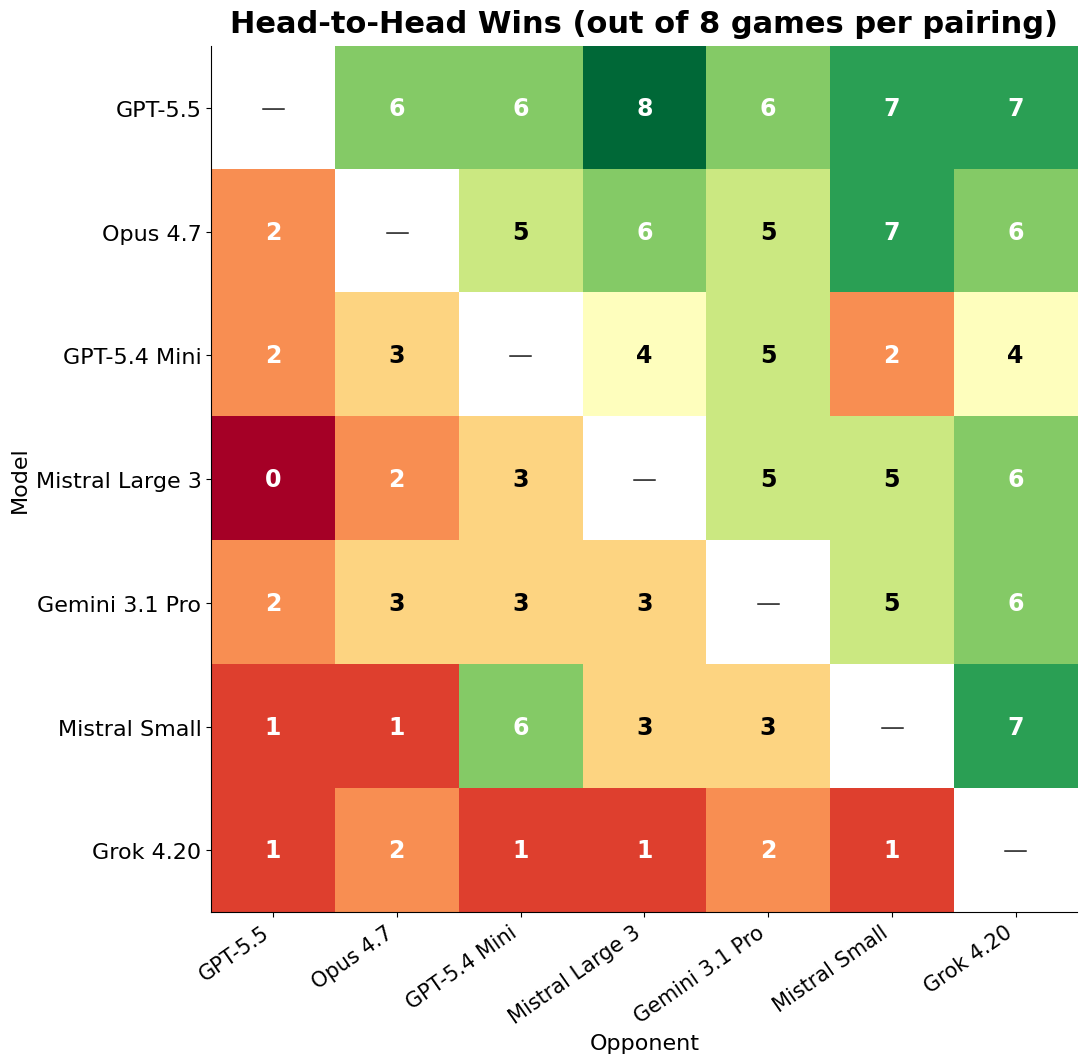
It is also interesting to see how much each model wins or loses in individual battles.
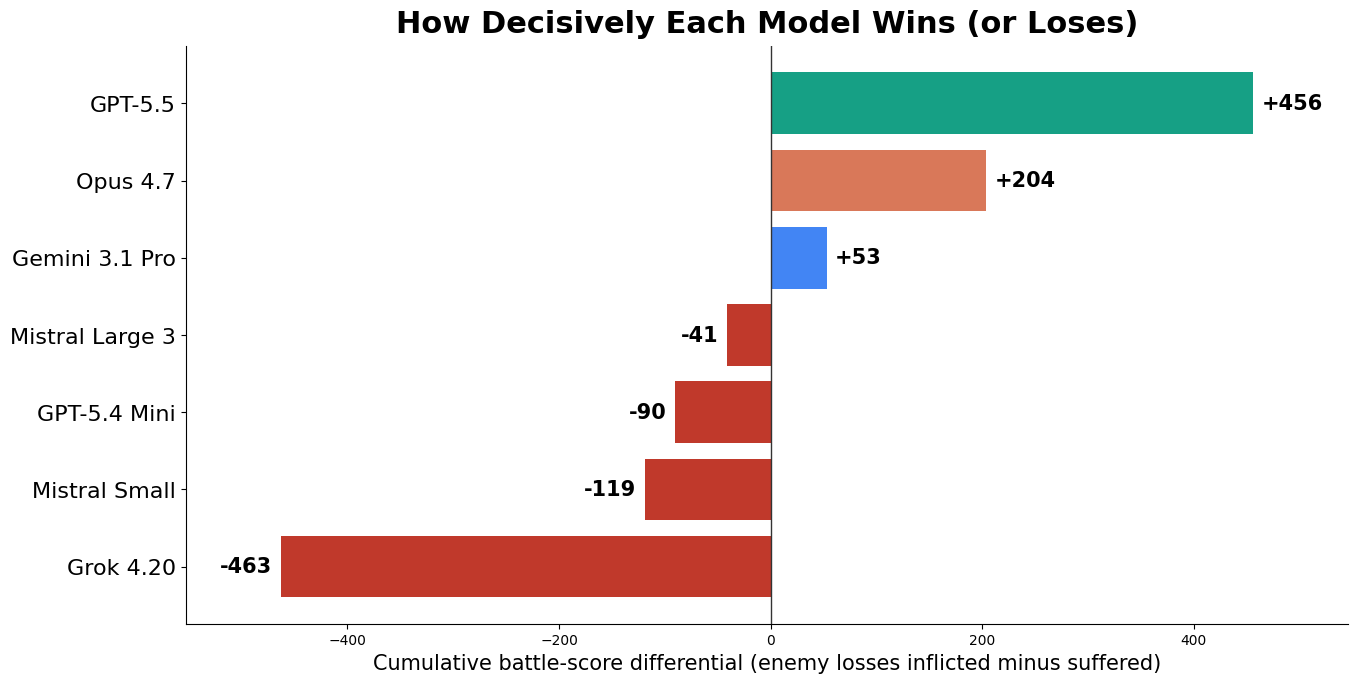
GPT-5.5 generally won decisively. Its cumulative battle-score differential was +456, ahead of Opus at +204. Gemini was only middle-table by record, but still positive on damage at +53, which suggests that its good games were genuinely good, and that it has a pretty aggressive approach. The three mid-tier models below it won plenty of games but bled units: Mistral Large finished at -41, GPT-5.4 Mini at -90, and Mistral Small at -119; Mistral seems to be the pro at Pyrrhic victories, which is theme-appropriate. Poor Grok suffered heavy losses each time (-463).
What do battles look like?
Interestingly, although they were not constrained to do so, most models deployed like Hellenistic generals: pike phalanx in the center, cavalry on the wings. Some decided (and it was a bad idea in general) to curl up their line into an almost-square formation. The most successful models wisely used their limited action points each turn; the bad ones (looking at you, Grok) wasted a lot of points in useless manoeuvres. I guess that must have happened to some real-life generals too.
Here is, for example, Gemini vs. Mistral Large. It's surprisingly even, with Gemini being its usual (?) aggressive self while Mistral maintains a defensive attitude, and ends up with Mistral winning by only a small margin.
Now here is Claude vs. Grok. Grok does score meaningful damage in the phalanx fight (which is mainly luck at first), but Claude takes much better advantage of the whole battlefield and destroys Grok's elephant, psiloi, thureophoroi and companion cavalry, before crushing the phalanx.
Nervos belli, pecuniam infinitam?
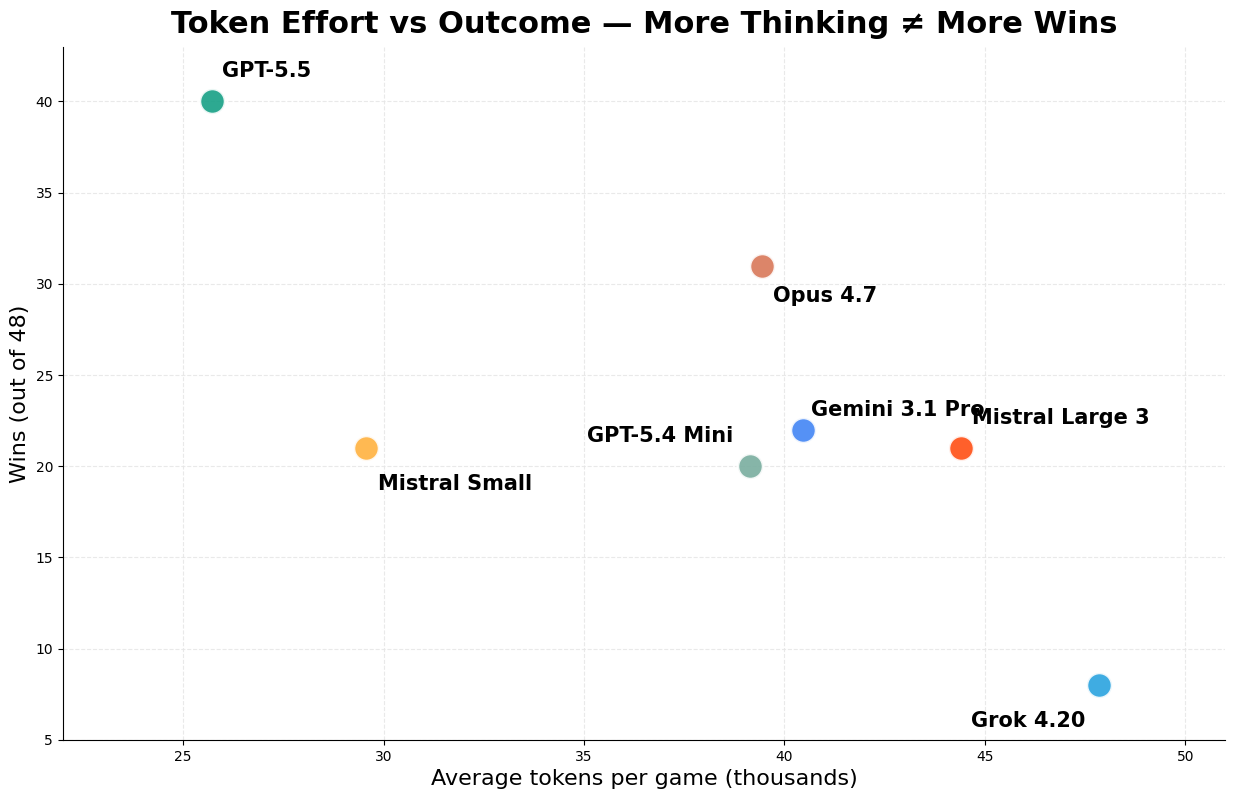
OK, but how do these LLM generals spend their money, that is, their tokens? Total tokens per game did not correlate with success. GPT-5.5 won the tournament while using only ~25.7k tokens per game, less than every model except Mistral Small. Grok used the most tokens, ~47.9k/game, and finished last. Mistral Large and Gemini also spent heavily, at ~44.4k and ~40.5k/game, but ended up in the middle. It reminded me of my favourite Napoleon quote: "There are a lot of good generals in Europe, but on a battlefield, they see too many things." Some models spent too many tokens deliberating and still failed to find clever actions.
Limitations and things to try
A serious caveat is that the models may not all have received exactly the same reasoning budget. I called them through OpenRouter with default settings, but each provider may interpret those defaults differently. For budget reasons, I did not run a tournament with every model pushed to its maximum thinking level; that would have been interesting, but much more expensive. Also, five games hit a max-action limit and were scored as unfinished; five model decision errors were counted as forfeits.
Of course, this is a highly simplified simulation of ancient battles. There is a square grid, which does not allow for wheels or oblique formations, command problems are very streamlined, morale is simplistic, and victory conditions count routed or destroyed units rather than control of the battlefield. But it is pretty neat that models rediscover some ancient tactics from first principles, or try to emulate them from their prior knowledge. Remember that this is an original game none of them has ever played. Presumably, they have not been trained much on this kind of stuff, so it is an interesting area to test their adaptability and capacity to think tactically.
Improving the engine, making it more realistic, trying different prompting structures (would models do better if they distinguished between overarching plans and individual actions?), and seeing how more models behave, such as Qwen or DeepSeek, would all be interesting directions for the future.
Are you a better general than GPT-5.5?
You can try and see for yourself! All the code, including a playable frontend (still very much in progress and missing many quality-of-life features), is public. Play for free against GPT-OSS (a pretty stupid commander) or, with your own API key, against any of the models above.
If the project interests you, don't hesitate to reach out or improve the repo directly. I would love to hear feedback.